
How Agentic AI Actually Consumes Publisher Content: Four Tiers Most People Haven't Mapped Yet
The publishing industry is focused on what happens when AI cites your content. But citation is just one layer. We break down the four tiers of how agentic AI actually consumes publisher content, from catalog access to the final click, and why understanding the full chain matters for any licensing conversation.
There's a conversation happening across the publishing industry right now about how to get paid when AI uses your content. It's a good conversation. Six months ago, most of the people I talked to couldn't clearly articulate the difference between AI training and inference. That's changed. The level of understanding has gone up significantly.
But there's a layer underneath that conversation that almost nobody is mapping yet.
Most of the discussion around inference licensing--whether it's RAG deals, pay-per-use models, or bulk library agreements--centers on a single event: the moment a publisher's content shows up in a final AI response. That event is real and measurable. But it's one piece of a much larger process, and understanding the full picture matters if you're going to make informed decisions about how your content gets used.
At Cashmere, we've been thinking about this in terms of four tiers. Not as a prescription for how licensing should work--the market is too early for anyone to be definitive about that--but as a framework for understanding what actually happens when an agentic AI system interacts with publisher content.
Why Agents Can't Piggyback on Google
The first thing to understand is that AI platforms like ChatGPT, Claude, and Perplexity can't use search indexes built by companies like Google. They have to build their own retrieval layer.
This is a fundamental difference from the old web model. In the traditional content funnel, Google indexed your content, users searched, clicked through, and you monetized that traffic. The infrastructure already existed. Publishers plugged into it.
Agentic AI doesn't work that way. These platforms need direct access to content--either through licensing agreements or by building their own indexes of premium material. That changes the economics entirely, because now the question isn't just "will my content appear in search results?" It's "will my content be available for an AI agent to query at all?"
The Four Tiers
When an AI agent processes a user's request using publisher content, there are four distinct stages where value is created. I think of these as tiers, and each one works differently.
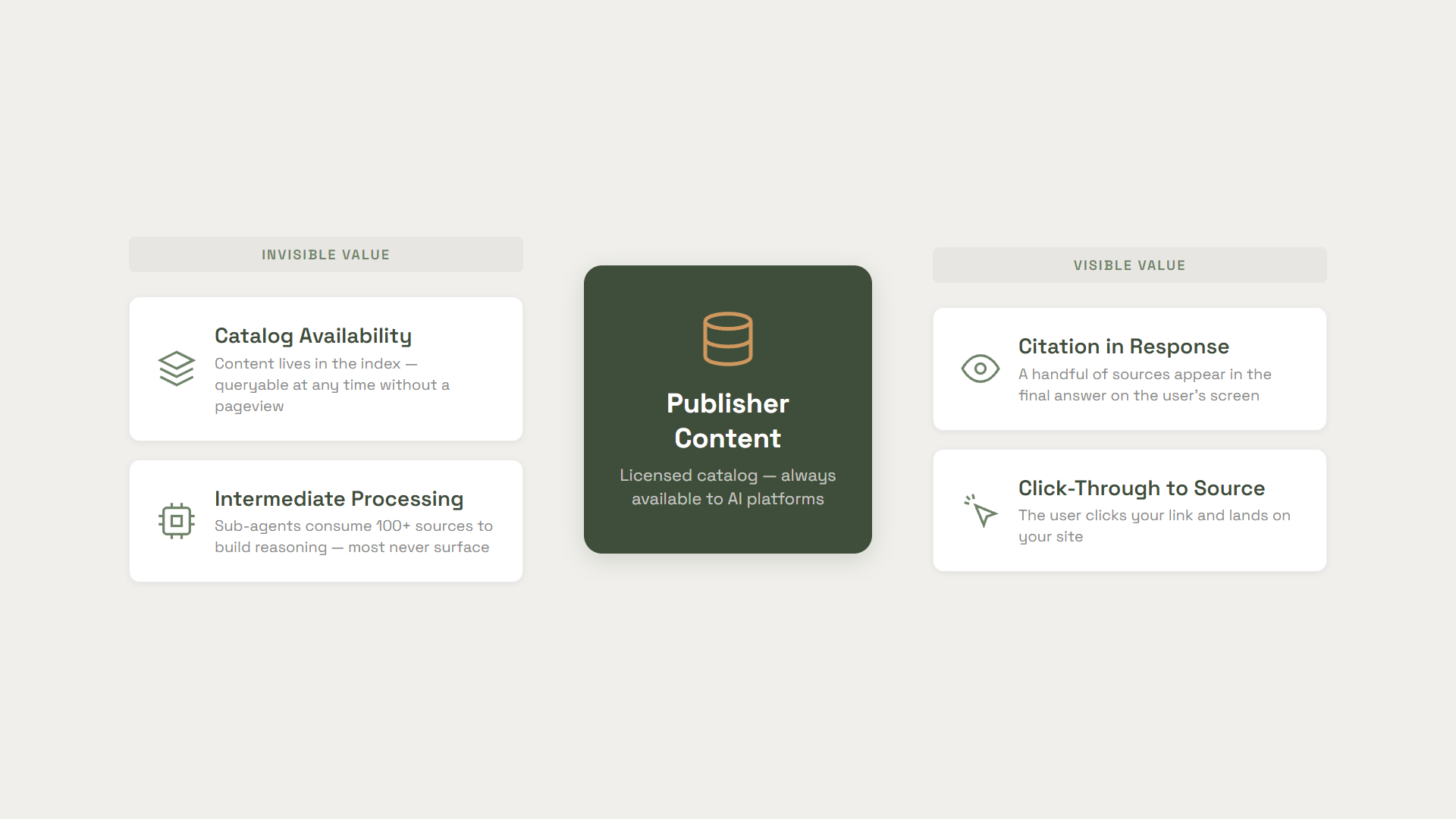
Tier 1: Catalog Availability
Every AI platform that wants to use premium content has to build its own index. ChatGPT can't query Google's index. Claude can't piggyback on Bing. They each have to construct a retrieval layer from scratch, and for specialized domains--medical literature, legal filings, financial research--that means licensing access to catalogs that no amount of web crawling can replicate.
Building and maintaining a premium content index is not free. It takes infrastructure, curation, and ongoing access agreements. That's Tier 1: the value inherent in simply having a specialized catalog available for an agent to query against, whether or not any specific piece of content is ever retrieved in a given session.
Tier 2: Intermediate Processing
This is the tier that's hardest to see from the outside, and it's worth spending time on because it explains a lot about how modern AI agents actually work.
As agentic systems become more autonomous, they don't just run a single query and return a result. They can spin up multiple sub-agents or threads simultaneously--each one searching for information, pulling content, and using what it finds to inform the next step. The data consumption happening in these intermediate steps is massive, and it's almost entirely invisible to the end user.
Here's the practical implication: an agent might consume 100 different sources in the process of answering a question, but only cite 10 in the final response. The other 90 informed the reasoning, shaped the answer, helped the agent eliminate dead ends--but they don't show up anywhere in the output.
That's a lot of content being used without any visible record of it.
Tier 3: Final Citation
Tier 3 is the event most people think of when they talk about inference licensing. The content appears in the final response--cited, linked, attributed. It gives the user visibility and confidence in the answer.
This is the most measurable tier, which is a big part of why it became the default unit for compensation models.
But Tier 3 doesn't account for all the content consumed in Tier 2. The citation is the tip of the iceberg.
Tier 4: The User Click
The fourth tier is when the user actually clicks on a cited source. This is where the publisher's direct relationship with the reader begins or resumes--it's the moment that can translate into a subscription sign-up, a purchase, or deeper engagement.
Publishers understand this tier intuitively because it maps to their existing revenue models. It's the closest thing to the old click-through funnel.
What This Means for the Compensation Conversation
I want to be clear about something: the market is early. Determining the "right" compensation model for publishers is an open challenge, and I don't think anyone--including us--has a definitive answer yet.
What I do think is that understanding these tiers matters for having better conversations about it.
There are a few different models starting to emerge. One approach is the agent paying to access a catalog and conduct searches, with a higher rate when content is actually cited in a final response. Another is more of a Spotify-like volume play, where agents pay a monthly fee and a platform provider assigns value to each tier of content usage. There are also bulk library licenses where the per-use question doesn't come into play at all--the publisher licenses their entire catalog for inference use at a flat rate.
Each of these models values the four tiers differently. And that's the point. Whether the tiers matter for any given deal depends on the structure of that deal.
For a bulk license covering an entire library, the granularity of Tier 2 intermediate processing may not be a factor--the publisher is compensated regardless of how many queries run against the catalog. But for pay-per-use models, understanding what's happening beneath the surface of a single citation becomes a lot more important.
The Bigger Shift
There's a broader change happening underneath all of this. The internet is fundamentally shifting from "open and free" to "closed and paid."
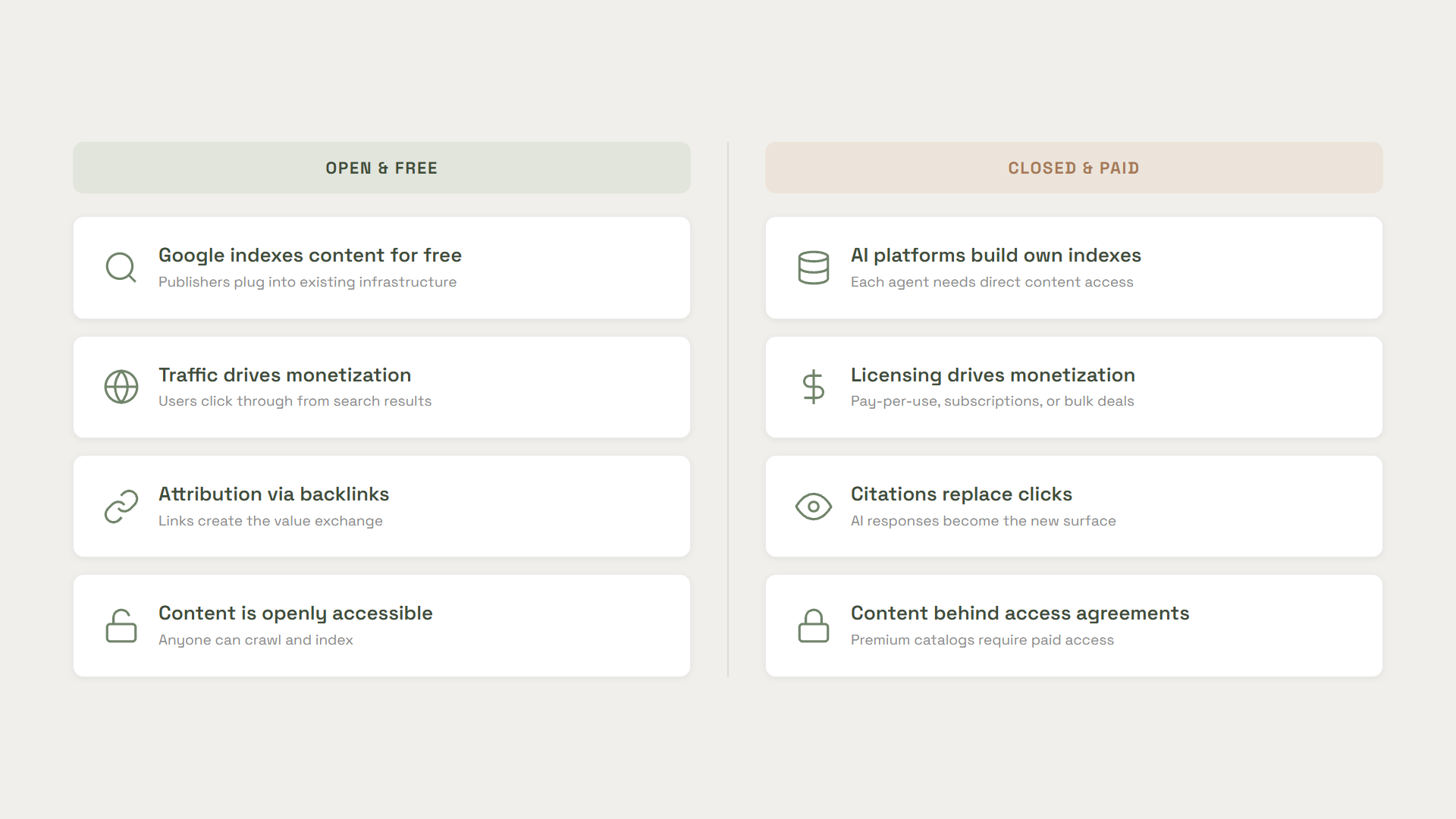
This isn't a prediction about the distant future. It's driven by a straightforward reality: AI agents are scraping and consuming content without providing the attribution or traffic that publishers relied on in the old model. If content is being consumed but no one is clicking through, the traditional monetization path breaks.
Content will eventually be paid for--directly by the user, through subscriptions, or via ads. We've seen these models play out before in streaming services like Netflix and Hulu. The specifics of how it plays out for publishing are still being worked out, but the direction is clear.
Where the Industry Is Right Now
At the London Book Fair and in conversations across the industry, I've noticed that very few people have mapped these tiers clearly. That's not a criticism--six months ago, most publishers I spoke with were still working through the basics of training versus inference. The fact that the conversation has moved this far, this fast, is genuinely encouraging.
But if there's one takeaway from this framework, it's this: the compensation question isn't just about what shows up in the final response. It's about understanding the full chain of how content gets used--from catalog access to intermediate processing to citation to click--so that whatever model a publisher agrees to, they're making that decision with full visibility into what's actually happening with their content.
Sources
Guest Post -- AI Isn't Going to Pay for Content. Part Two: The Path Forward -- Scholarly Kitchen
Stay in the loop
Get the latest insights on AI, content licensing, and the future of publishing.
