
The Current State of AI and Publishing (2 of 4)
This second article analyzes partnerships Digital Publishers have made with AI companies and sets the stage for why these won't work for Book Publishers.
Designers: Jonathan Woahn, Michael Moulton / Tools: MidJourney, Recraft, Photoshop
In the previous article, we explored the legitimate concerns book publishers have about AI—consent, credit, and compensation—and set the stage for why the industry needs a joint vision between AI companies and publishers. Now let's examine what's actually happening in the market.
When the Game Changed
On November 30, 2022, OpenAI launched ChatGPT. It reached 1 million users in just 5 days. Within 2 months, it hit 100 million users—making it the fastest-growing consumer application in history.
The world was simultaneously amazed and terrified. AI could write essays, debug code, draft legal documents, summarize research papers, and hold conversations that felt eerily human. Everyone—from students to CEOs—started asking the same question: "Is AI going to take my job?"
But for publishers, a different question was brewing.
"Hey AI Companies, Where'd You Get That Data From?"
About seven months after ChatGPT's launch, the first major lawsuit landed. In July 2023, authors Mona Awad and Paul Tremblay filed suit against OpenAI, alleging that the company had used their copyrighted books to train its models without permission.
Remember the Art of War example from the previous article? When I asked ChatGPT to reproduce the first chapter, it did so nearly word-for-word. That kind of capability raised a simple but explosive question: if the AI can reproduce content, it must have been trained on that content. And if it was trained on it, who gave permission?
Dozens of similar lawsuits followed. The New York Times sued Microsoft and OpenAI. StackOverflow's community erupted over data being used without consent. Reddit users protested. The message was clear: content creators were not going to sit quietly while their work was used to build billion-dollar AI systems.
Solving for Consent, Credit, and Compensation
The lawsuits forced a reckoning—and some companies moved faster than others to address the core concerns.
Reddit provides the clearest case study. In early 2024, Reddit changed its API (Application Programming Interface—essentially the technical gateway that allows external services to access Reddit's data) policies and signed a deal with Google reportedly worth $60 million per year. In exchange, Google gained structured access to Reddit's massive corpus of user-generated content for AI training and search integration.
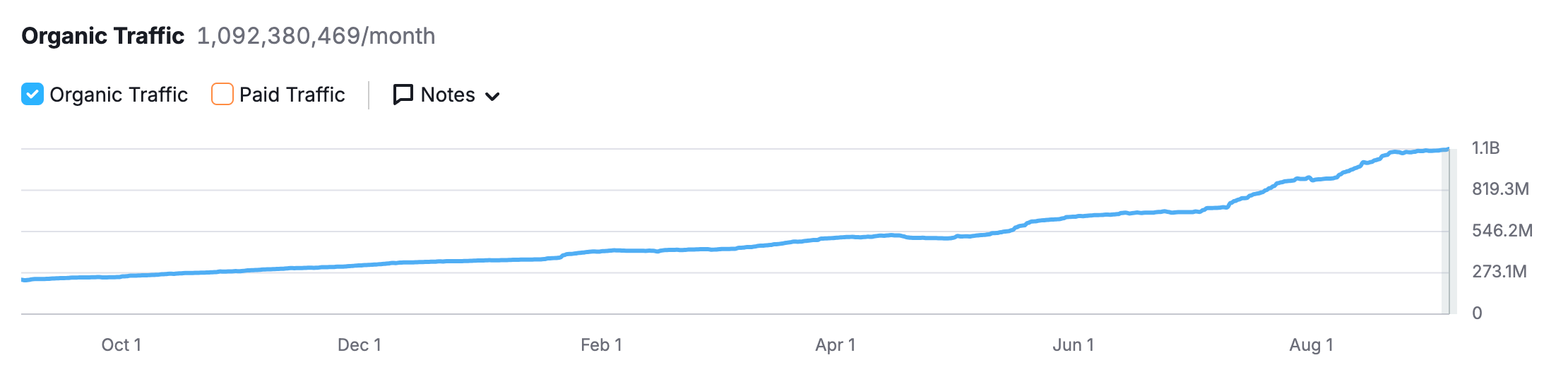
In Sept. 2023, Reddit saw about 220MM monthly users to their site. Shifting their business model led to increasing their site traffic by over 500%. Source: SEMRush
The deal addressed all three core concerns:
Consent: Reddit explicitly licensed its data through a formal agreement. No ambiguity—no scraping in the shadows.
Credit: Reddit content began appearing prominently in Google search results, with clear attribution back to the original posts and communities. Users searching for answers would see Reddit threads surfaced directly, driving traffic back to the platform.
Compensation: Reddit received substantial upfront payments and ongoing revenue, creating a new business line that fundamentally improved its economics—as reflected in the dramatic traffic increase shown above.
Licensing Data for Use with AI: A New Revenue Model
Reddit's deal opened the floodgates. Other major digital publishers quickly followed:
- Condé Nast (Vogue, The New Yorker, Wired) signed licensing agreements with AI companies
- Time licensed its century-deep archive
- Vox Media (The Verge, SB Nation) struck deals for content access
- The Atlantic partnered with OpenAI
- NewsCorp signed a deal reportedly worth $250 million over 5 years, covering The Wall Street Journal, New York Post, and other properties
A new revenue model was emerging: publishers could license their content to AI companies in exchange for compensation, attribution, and control over how their data was used.
Digital Publisher Content Licensing for Usage with AI Companies
I want to be intentional about using the phrase "digital publishers" here—as distinct from "book publishers." This distinction will become critical in the next article.
For context, Wiley—one of the world's largest academic publishers—reported a $44 million AI licensing deal, demonstrating that even traditional publishers with significant book catalogs are finding opportunities on the digital side of their business.
A disclaimer: Many of these deals involve non-public details. What follows is based on publicly available information, industry analysis, and informed inference. The specifics may differ from what's happening behind closed doors.
Also, if you haven't already, I'd strongly recommend reading the Beginner's Guide to Understanding Generative AI before continuing, as the concepts of training and inference are critical to what follows.
Training
When digital publishers license data for AI training, the model is typically perpetual, per-model licensing. This means a publisher grants access to their content for training a specific version of an AI model.
To understand why this matters, consider how AI models evolve. OpenAI didn't just build one model—they built GPT-2, then GPT-3, then GPT-3.5, then GPT-4, then GPT-4o, then GPT-4o1, and so on. Each generation is a fundamentally new model that needs to be trained from scratch (or nearly so).
This means publishers can license their data for each new model generation—creating a recurring (if lumpy) revenue stream. Each time a company wants to train a new model, they need to negotiate new access.
The data used in training is distinct from data used in inference—a critical distinction we'll explore next.
Credit
Credit during training is inherently problematic—and this applies to all content types, not just books.
Think of it like learning piano. Two scenarios illustrate the challenge:
Scenario 1: The Inability to Provide Sources. Imagine someone who has studied piano for 20 years. They've learned hundreds of pieces—Bach, Chopin, jazz standards, pop songs. Now they sit down and improvise a beautiful new melody. If you asked them, "Where did that come from? Which piece inspired that particular phrase?"—they probably couldn't tell you. The influences are so deeply internalized that they can't be untangled.
This is exactly what happens with AI training. The model ingests millions of documents and internalizes patterns, relationships, and structures. When it generates output, it can't point to specific sources—because the output is a synthesis of everything it's learned, blended together in ways that defy simple attribution.
Scenario 2: The Training Soup. Now imagine blending ingredients to make a soup. Once blended, you can't separate the tomatoes from the basil from the onions. They've become something new. AI training works the same way—individual content sources are blended into the model's parameters in ways that make exact attribution essentially impossible.
This is a self-referential challenge: the very process that makes AI powerful (synthesizing vast amounts of content into coherent understanding) is the same process that makes credit during training nearly impossible.
Digital Publisher Content Licensing: Inference
If training is where an AI model learns, inference is where it works—answering questions, generating content, and serving users in real-time.
Consent and Compensation
For digital publishers, inference licensing typically works through API-based access control. The publisher provides structured access to their current content through an API, and the AI platform pays for that access on an ongoing basis.
This is similar to how Reddit restructured its API. Instead of allowing free, unlimited scraping, Reddit now requires AI companies to access data through controlled channels with clear terms and pricing. The publisher controls the tap—and gets paid every time it flows.
This consumption-based model aligns incentives beautifully: the more useful the content, the more it's accessed, and the more the publisher earns.
Credit
Credit during inference is where digital publishers have their greatest strength. This is the most powerful and differentiated aspect of inference licensing.
Think back to the piano analogy. If training is like internalizing music over years of study, inference with real-time data access is like sight-reading—reading sheet music in real-time and performing it on the spot. The "sheet music" (the publisher's content) is right there, visible and attributable.
When an AI system uses RAG (Retrieval-Augmented Generation) with a publisher's content during inference, it can cite the source directly. The user can verify the information. The publisher gets attribution and, potentially, traffic.
This is fundamentally different from training. During inference with real-time data access, the content is accessed, used, and credited in a transparent, traceable way. Through RAG with private data sets, AI systems can ground their responses in specific, up-to-date, licensed content—creating a virtuous cycle of quality, trust, and compensation.
The Devil Is in the Details
Let's summarize what we've covered with a matrix:

For digital publishers, the 3C's framework looks quite healthy:
- Training: Consent and Compensation are solved through perpetual licensing. Credit remains inherently difficult (marked yellow/red) due to the nature of how training works.
- Inference: All three C's can be addressed—Consent through API access, Credit through RAG and attribution, and Compensation through usage-based payment models.
This is why digital publishers have been relatively successful in navigating the AI landscape. They have the tools, the infrastructure, and the business models to participate in both training and inference markets.
But what about book publishers? As we'll see in the next article, the story is very different.
This is Part 2 of a 4-part series on AI and the Future of Book Publishing:
- AI and the Future of Book Publishing
- The Current State of AI and Publishing
- Why the Established AI Content Licensing Model Breaks with Books
- Vision and Call to Action for AI and the Future of Books
Companion article: A Beginner's Guide to Understanding Generative AI
Stay in the loop
Get the latest insights on AI, content licensing, and the future of publishing.
