
A quick introduction
This is a companion article to my series on AI and the future of Book Publishing. It is written specifically for those in the book industry and provides critical context for the ideas I discuss in that series.
That said, the concepts here should be relatable to anyone. I wrote it without assuming the reader has any prior understanding of AI other than colloquial exposure to some concepts.
I focus specifically on how Generative Text AI works and the implications for the book industry, using examples and simple analogies to help the reader connect with and remember the content.
Enjoy!
Let's first align on some basic vocabulary
One of my principles comes from The 7 Habits of Highly Effective People, "Seek first to understand before being understood".
For this reason, we need to first seek an understanding of generative AI technology before understanding its implications for book publishing.
You may or may not be as excited to read this article as I was to write it, but I cannot sufficiently emphasize how critical it is for anyone interested in this space to have a fundamental grasp of how generative AI works.
For that reason, I've tried to make these ideas fun and easy to relate to.
I've taken liberties to omit key details for the sake of relatability — so to anyone reading this with a deeper understanding of AI, send me a note and we can discuss it further.
Some key vocabulary for this section:
- AI — Artificial Intelligence. A general "catch-all" term that refers to a system that can understand, generate, and interact via text, audio, video, etc.
- Foundational Model, aka "Model" — Set of mathematical instructions that have been programmed to accomplish a particular task. For instance, there are different types of “models” that generate text, images, video, audio, etc.
- LLM — A type of Foundational Model, called Large Language Model. Specifically works with understanding and generating text. The model that ChatGPT uses (called GPT3, GPT4, etc.) is an example of an LLM
- ChatGPT — A popular AI chatbot application many people recognize when they think of "AI"
- OpenAI — The parent company that built ChatGPT
There are many different fields and types of AI, but for this article, we will be primarily focused on LLMs as they have the most direct relevance to current state book publishing.
Artificial Intelligence today is not actual "intelligence"
Let's be clear about something.
Let's be clear about something: When you go to ChatGPT and ask it a question, ChatGPT isn’t "thinking." Instead, it’s predicting the sequence of letters to respond with — based on the words you initially provided it (the “input”).
Someday we might have true “thinking, reasoning, considering” AI, but that day is not today.
Instead of thinking, ChatGPT uses complex statistical methods to take the prompt you provide, and then predict which letter makes the most sense to follow the previous one.
It turns out that people are pretty good at this as well; let’s look at some examples to illustrate what I mean.
Predicting Common Phrases
Let’s try a quick exercise. I'll provide you with the first part of an English colloquialism with some minimal context. See if you can figure out how to complete each phrase (the answers are at the end of this article):
- Your friend is about to star in a play. You say to them, “Break a ____”
- You easily complete a complicated task. When asked if it was hard, you say “It was a piece of ____”
- Someone tells you a secret, and you assure them, “My lips are ____”
- You’re struggling with a project, but a friend reassures you, “Don’t worry, two heads are better than ___”
- A friend offers to help you move, and you reply, “That would be a load off my ____”
Not knowing anything about you (and assuming you speak English), I'd be willing to bet you answered most if not all of them correctly.
At its core, an LLM does the same thing as your brain did in this example.
The main difference is instead of predicting the next single word like in these examples, they’re capable of extending the prediction into sentences, paragraphs, and entire narratives.
How is an LLM able to create its predictions?
The short answer is complex math.
I'm not yet qualified to give a longer answer (although this resource provides a fantastic interactive visualization of what’s going on under the hood), but I can give some simple examples to help conceptualize what’s happening.
The Magic Box Analogy
Imagine we have a magic box. When you feed a number into this magic box, it does something to it and then creates a different number as an output.
I'll provide you with a couple of magic boxes with examples. Let’s see if you can figure out what the “rule” is for each of the magic boxes (answers at the end of the article).
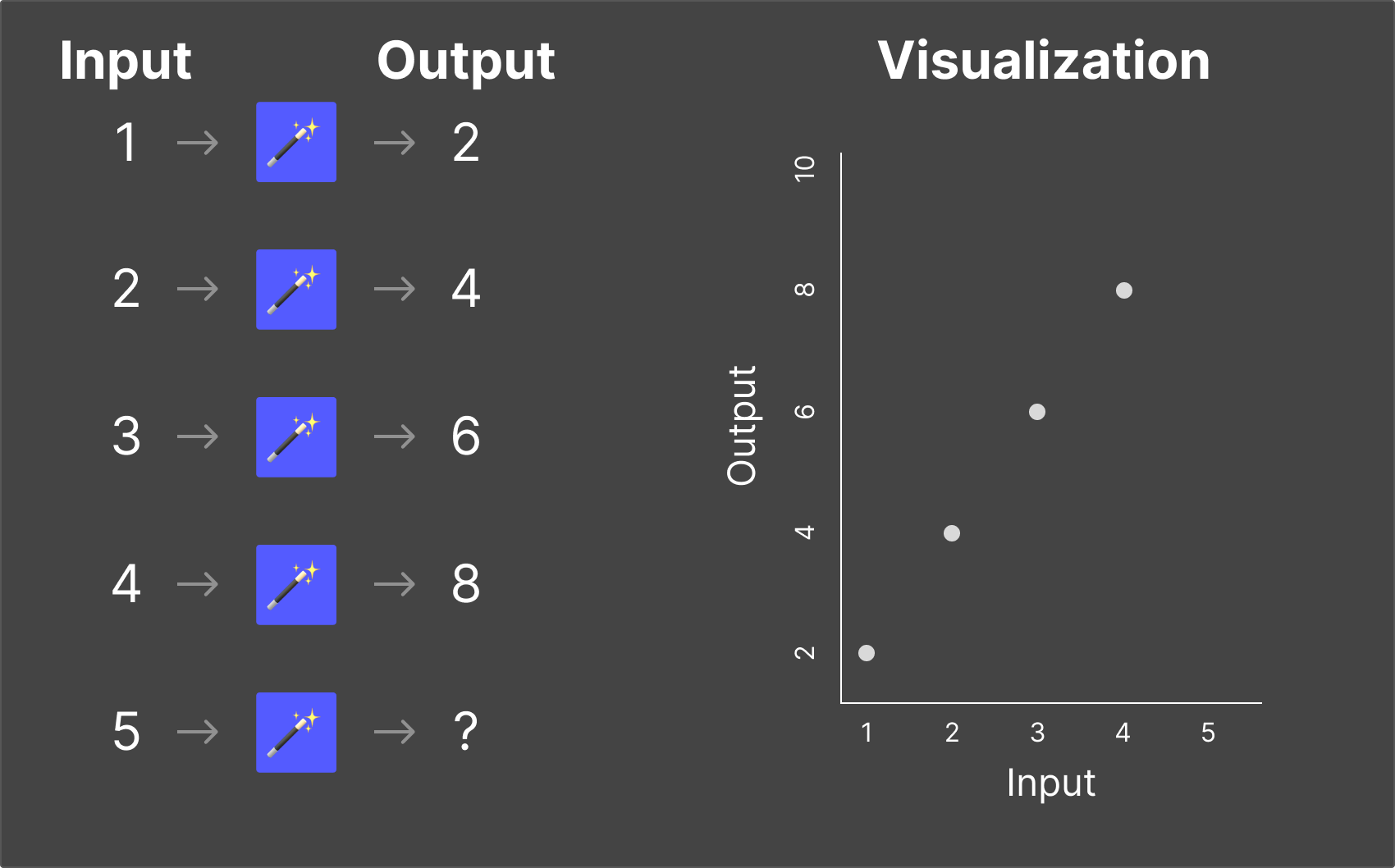
Using the Magic Box #1 as an example, the way to think about these is “When ‘1’ is put in the box, you get ‘2’ out. When ‘2’ is put in, you get ‘4’ out.”, and so forth.
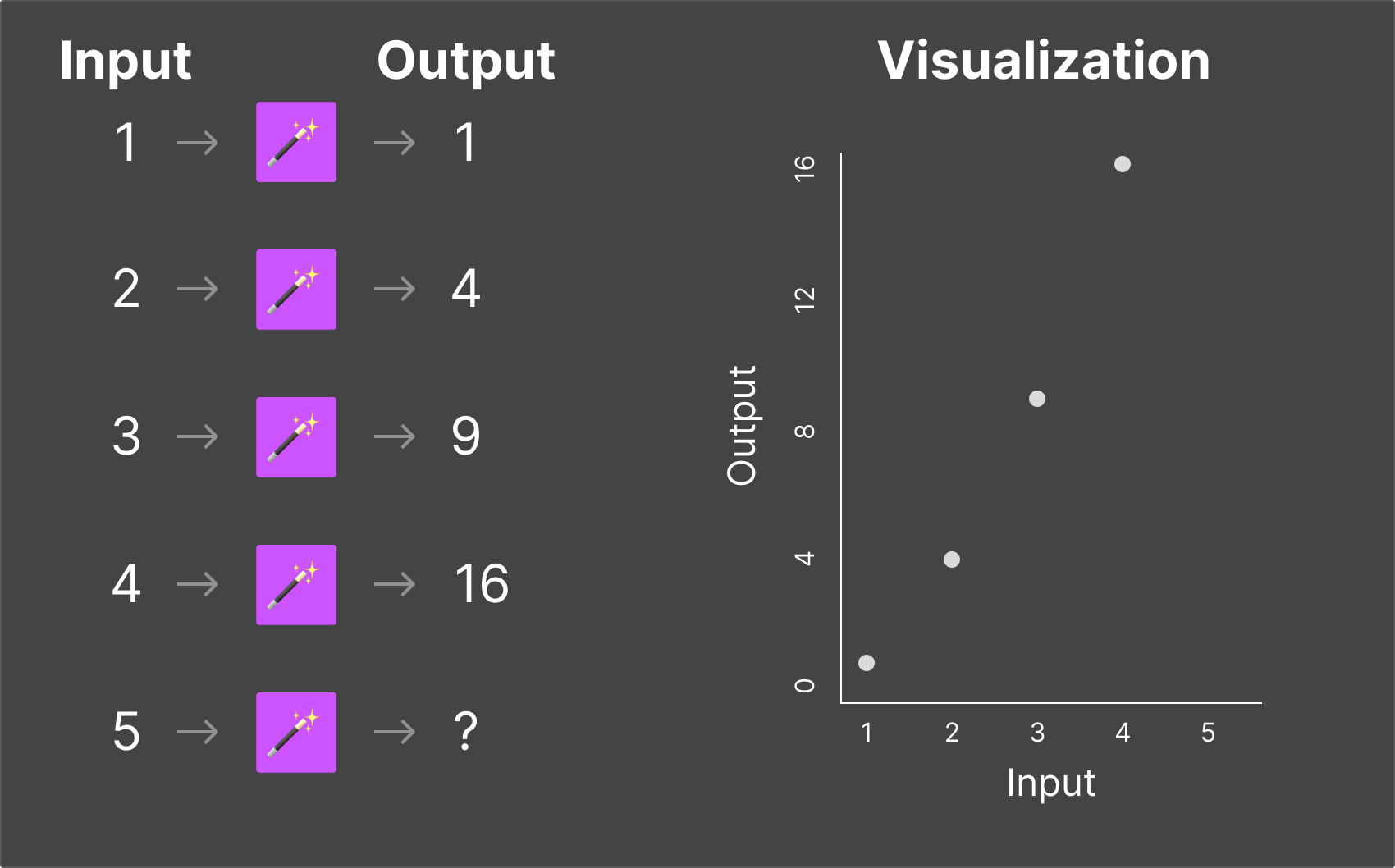
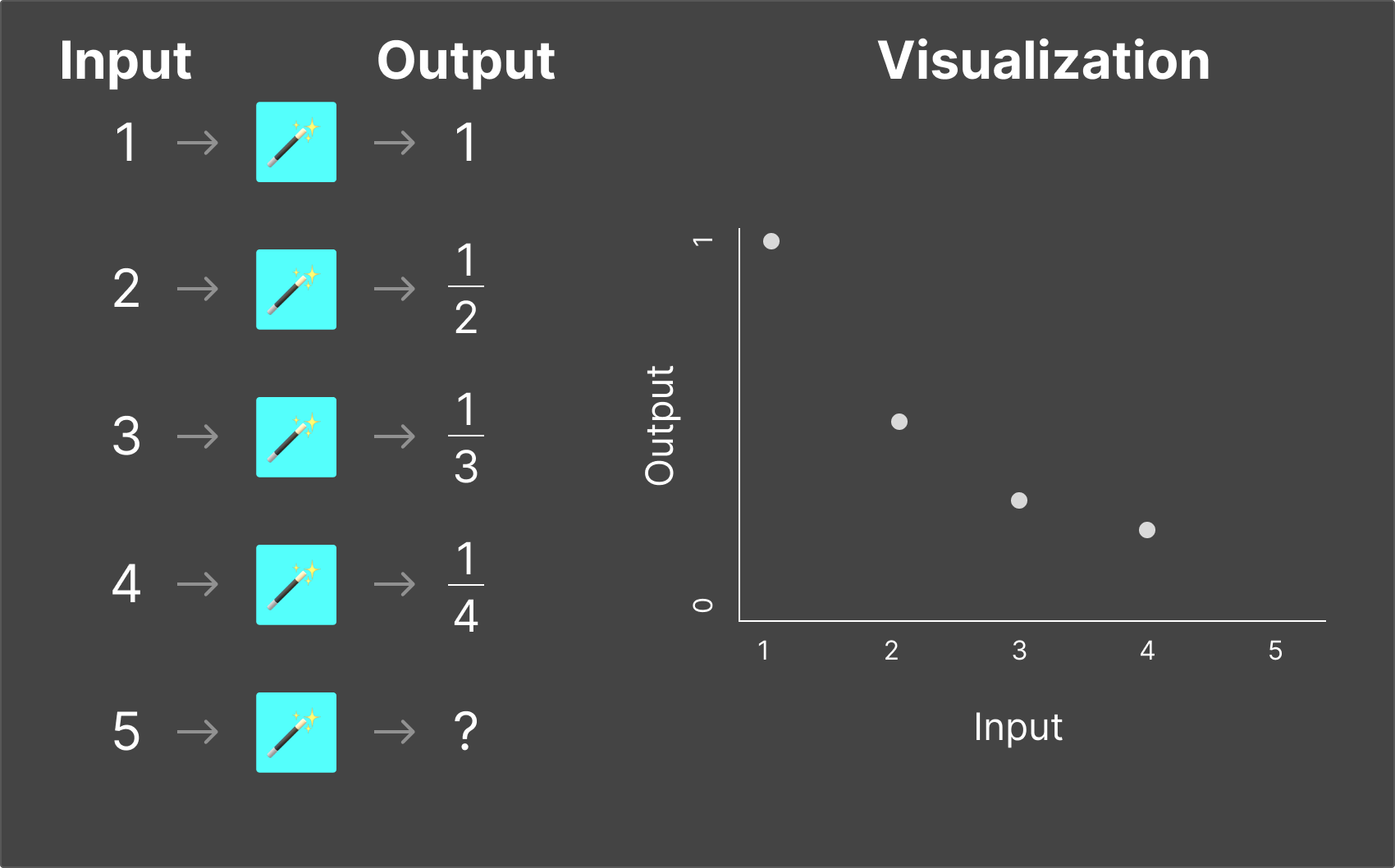
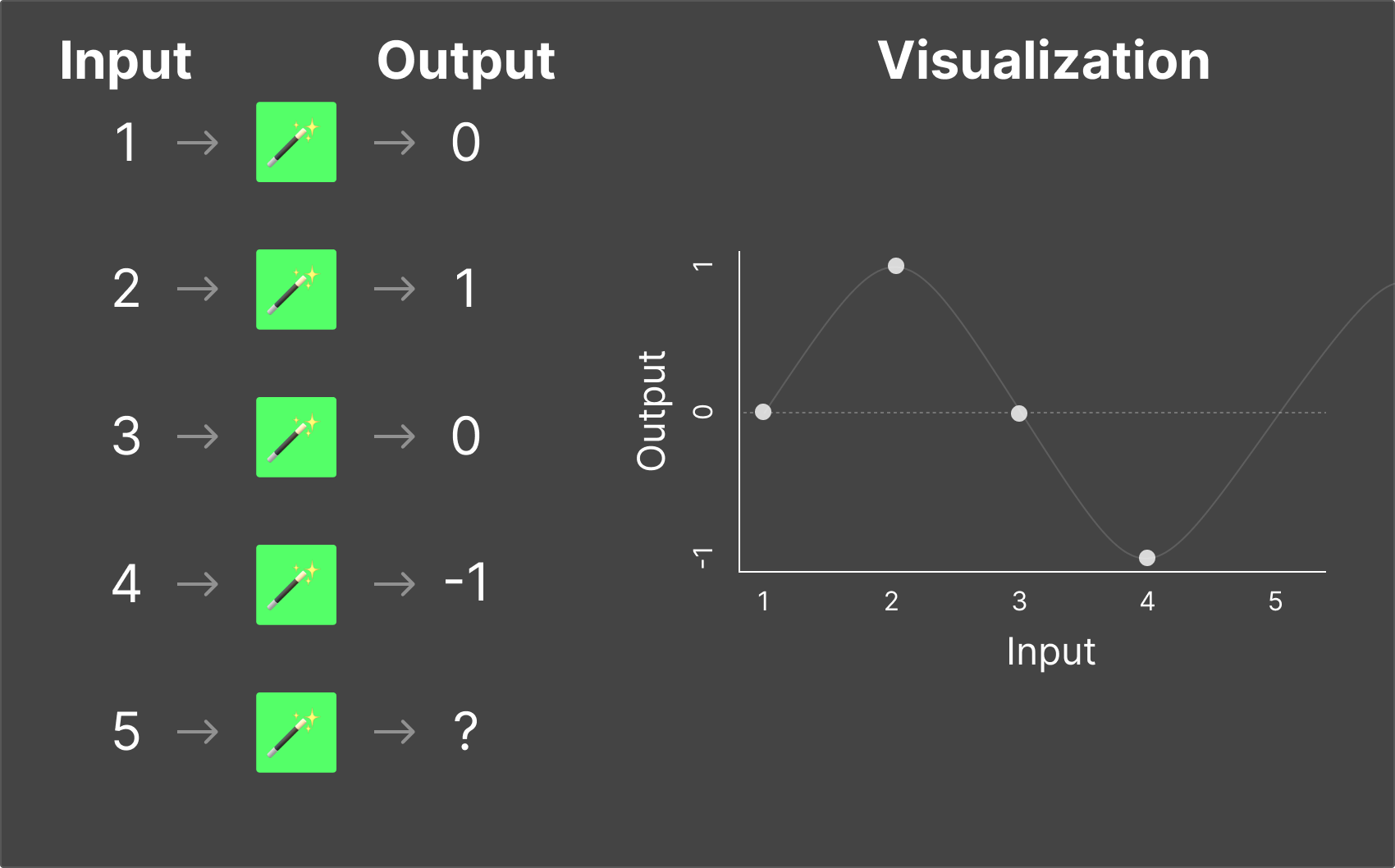
For each of the magic boxes, you need to figure out what the output would be when you put “5” into them.
📦 Magic Box #1
📦 Magic Box #2
📦 Magic Box #3
📦 Magic Box #4
How'd you do? Again, not knowing anything about you, I'd bet you did very well.
These examples are very basic, and even if you didn’t know the exact mathematical function, you were probably able to pick up the pattern easily enough that you could confidently answer the output from the magic box for nearly any input value.
What we've done here is simply illustrate the two major fields of science around LLMs: Training and Inference.
"Training" is where an LLM learns the rules of a system
Training is the process of teaching an LLM the rules of a system so that when given an input, it can accurately predict the output (which is called “inference,” and we’ll talk about it shortly).
Referring to our magic box example above, the box represents the LLM itself, and you, the reader, represent the engineer training the LLM.
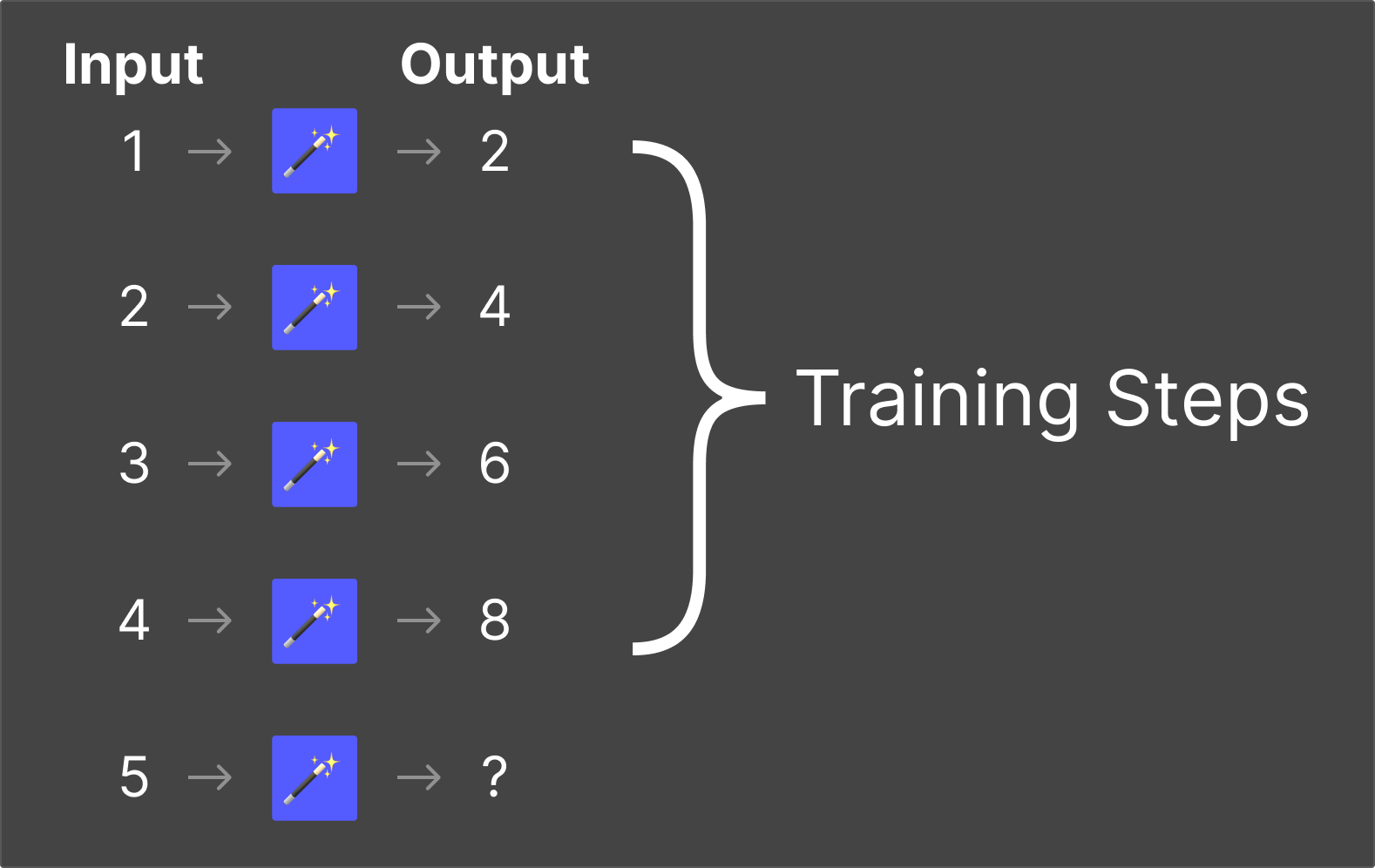
The first few examples you feed the box represent “training” data.
You know the input and the output, and the magic box is trying to figure out the rules of the system so it can predict the output when it’s not provided.
Once the LLM has been trained and the engineer is satisfied with its performance, the LLM can generate a response for any given input — even if it hasn’t seen that specific input before — which is where Inference comes into play.
"Inference" is where the LLM applies its Training
Inference is the process of using the patterns an LLM learned during training to generate predictions based on new input.
Your brain already did this in our magic box example.
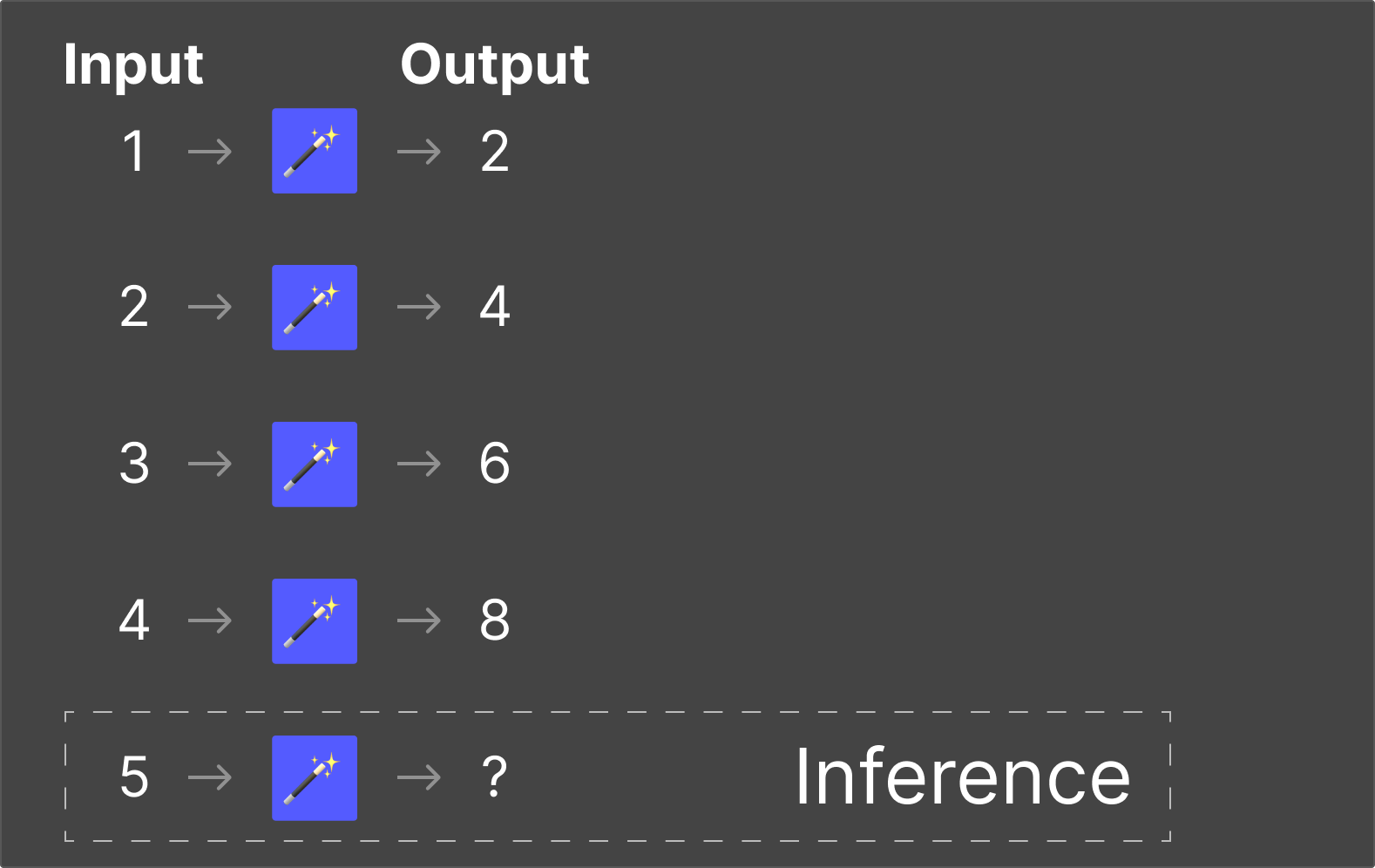
Once you learned the rules for any of the magic boxes, you could quickly predict an accurate response for any number I gave you — even if that number wasn’t in the training data.
"Hallucinations" are when an LLM makes up an answer during inference
When an LLM is trained, the training data cannot possibly cover every possible scenario.
In our example above, “5” was not part of the training data, but given the historical values, we can probably safely assume we know the rule for what the answer should be.
But what if that’s not how reality works?
For instance, what if we put “-1” into our magic box? Based on our training, we would assume the output should probably be “-2”.
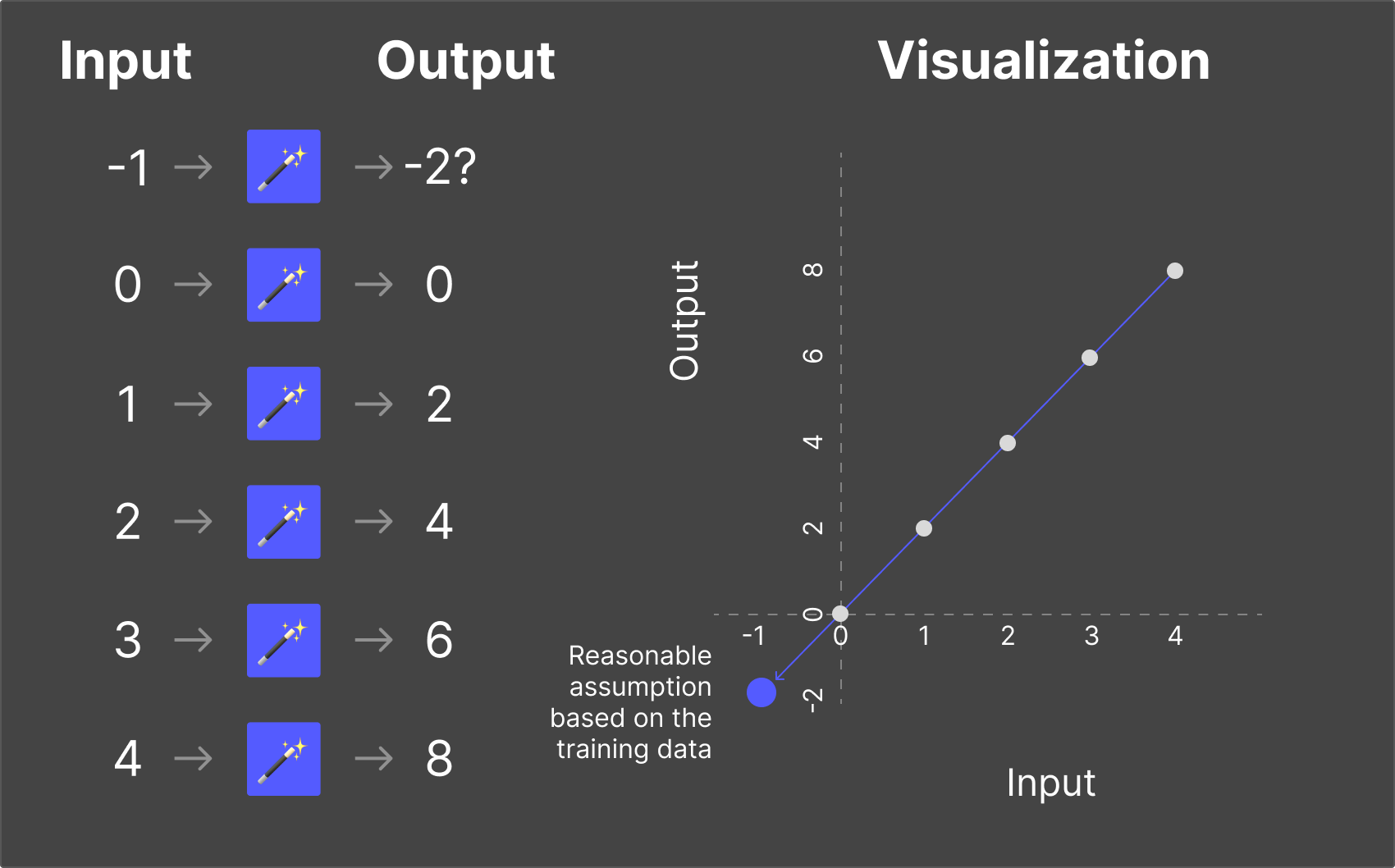
But what if in reality, when inputs are below 0, the outputs look like this?
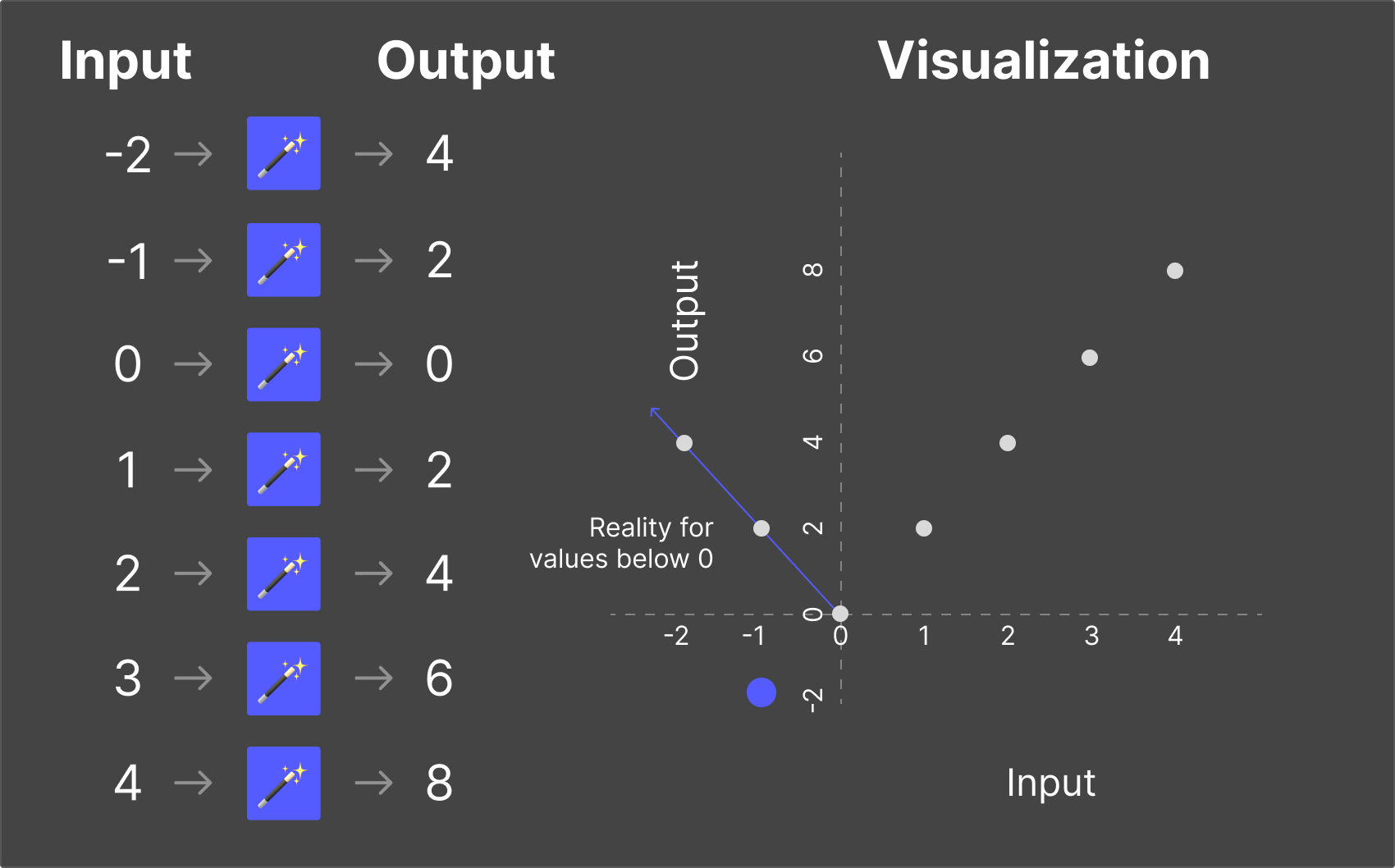
The rules that we trained ourselves on based on the original training data no longer hold, and we would have to retrain the model.
The key thing to understand here is that hallucination is the LLM's best attempt to respond to every question, even if it doesn’t know the answer.
Does an LLM recall training data for inference?
It is important to note that the LLM does not retain a copy of the data used to train it.
And by “copy”, I mean, when you’re writing a document on your computer, you save it on your computer or your cloud, and there’s an actual file that contains all the text of your document. LLMs do not do this.
Since the LLM generates a prediction of the next word (or letter) one at a time and it does not keep a copy of the training data, there is no way for the LLM to check its results to see if they’re accurate.
However, since the LLM used the training data to learn the rules of the system, it often accurately predicts responses that are extremely close, if not identical, to the training data itself.
Remember what ChatGPT did with The Art of War example from earlier?
In the Art of War example, ChatGPT was not retrieving the text from a file stored in memory somewhere; instead, it was predicting what the text of the book should be, based on its training data.
This is a critical point to understand as it pertains to book publishers and their concerns, which we will dig into further shortly.
An analogy to help illustrate the significance of this point.

Imagine you’re learning to play a song on the piano.
You purchase sheet music of your favorite artists’ top hits and practice it over and over again, committing the notes to memory.
After a while, you can play the piece without looking at the sheet music because your brain has internalized the pattern of notes, chords, and timing — in effect, you’re predicting each of the next notes in their proper sequence.
You can now perform the piece for your family or as a fun “party trick” with friends. You become known as the pianist in your social circles, reproducing the music from memory.
This is similar to how an LLM works once it has been trained on the data; once the model “knows” information, it cannot be deleted or removed.
Just like you learning to play the piano, you can remove the sheet music, but your brain still retains the training that will always allow you to recreate the music.
For an LLM, once the training process is complete, the data is now part of the LLM. There is no file sitting in a folder somewhere waiting to be hacked or deleted — it’s now part of the LLM just like music is now part of your brain.
How does an LLM stay current with new data?
The process of training an LLM is a distinct event — it has a beginning, a middle, and an end.
Once the training is completed, tested, and vetted, developers release the LLM to the public with much publicity and fanfare.
Since training an LLM has a “start date”, by default this means the training data can only be as current as the data available when it started training. So if an LLM takes 3 months to train, that means it will have a 3-month knowledge gap by the time the LLM finishes training.
In the early days of ChatGPT, there was a well-known issue with the knowledge cut-off date of September 2021. That was the most recent date for information to have made it into the LLM’s training data.
Training a foundational model n LLM like GPT4 costs tens, if not hundreds of millions of dollars and consumes thousands of GPU processing years (which is shortened into weeks and months through parallel computing).
For this reason, it’s impractical to retrain an LLM just to get new information into it.
Fortunately, there are multiple faster, lower-cost options for LLMs to work with data that was not part of the original training data.
The two main ways of updating a model after it has been trained are call "Fine Tuning" and "Results-Augmented Generation" (RAG)
What is "Fine-Tuning"?
Fine-tuning allows you to update an existing LLM without retraining it from scratch — think of it as giving the AI a focused lesson on a very specific subject.
While fine-tuning can generate new "knowledge" for an LLM, it is most often used to alter the model’s behavior.
For instance, in the earlier piano analogy, what if you wanted to change how you played the piece? Maybe adjust the tempo, improve the dynamics, or update the mood?
These changes can take place without you having to learn the entire song from scratch again, it just takes some time for you to practice playing it with the actual changes you want to make.
With an LLM, it’s similar. Perhaps you want it to understand or speak legal jargon better, or better align the LLM’s tone with that of your brand.
Fine-tuning allows a model to be updated in specific areas without retraining it from scratch.
What is "Results-Augmented Generation" (RAG)?
All LLMs have what’s called the “context window,” which is basically how much information you can pass as input into the LLM for inference.
An easy way to think about a context window is the short-term memory of an LLM.
In the early days, the context window was so small that if you talked to ChatGPT for longer than a few messages, it would start “forgetting” the first things you discussed with it.
Today, context windows are much larger and less of an issue than they were in the early days. Some of the latest models are so big they can fit multiple books’ worth of text into them.
The way RAG works is you feed the information you need the LLM to analyze into the context window, and then it provides a response based only on the information it received.
In most instances where people talk about “training a model” for some specific use case (e.g., a customer support client), this is what they’re usually referring to.
The model isn’t actually trained on the support data, but rather it has access to all of the information, and just like you do when you’re looking for an answer on Google, it searches through the data to find what it’s looking for, and then pulls it into the context window and generates a synthesized response.
A simple analogy to illustrate how RAG works is like a human customer support representative.
They may not know all of the answers off the top of their head, but they have access to a massive database of troubleshooting issues.
When presented with an issue, they can search it, find the relevant information, and then synthesize it back as a response to help customers answer their problems.
In this example, the customer support rep is the LLM, the database of troubleshooting issues is the data you feed into the context window, and the response to the customer is the response you get back from the LLM.
What did we learn about LLMs?
Understanding how LLMs process and generate text is essential to a productive conversation addressing the opportunity AI could play for book publishers.
In this section, we discussed:
- AI today isn’t actually “intelligent”, but rather good at predictions
- Two main fields of science govern how AI LLMs are built and operate: Training and Inference
- Training is the process of teaching an LLM the rules of a system
- Inference is how the LLM is used once it has been trained
- Hallucinations are when an LLM imagines a response based on its training data, yet does not match reality
- Training data is not stored by the LLM but recreated through advanced predictions
- A context window is like short-term memory and is the data used for inference
- After an LLM has been trained, Fine-Tuning can be used to update its behavior, and RAG (Results-Augmented Generation) can provide it with access to new information
By demystifying the technology, we are now ready to explore better how AI can be a powerful ally for book publishers rather than something to be feared.
I hope you’ve enjoyed this article! If you’d like to learn more about the implications of AI on the future of Book Publishing, please check out the rest of this series through the links below.
- AI and the Future of Book Publishing
- The Current State of AI and Publishing
- Why the Established AI Content Licensing Model Breaks with Books
- Vision and Call to Action for the Future of Books and AI
.jpg)

