
In the previous article, we identified the key concerns for publishers that AI represents a loss of control of data; by disregarding consent, credit and compensation of their IP. We evaluated the validity of those concerns and then provided an outline of what this series would cover.
In this article, we will continue that conversation by discussing what’s currently happening in the industry and how those relationships are likely addressing the previously established concerns.
When the game changed
The world shook when ChatGPT was introduced in November of 2022.
It took 5 days for ChatGPT to reach 1MM users, and it reached over 100MM within 2 months.
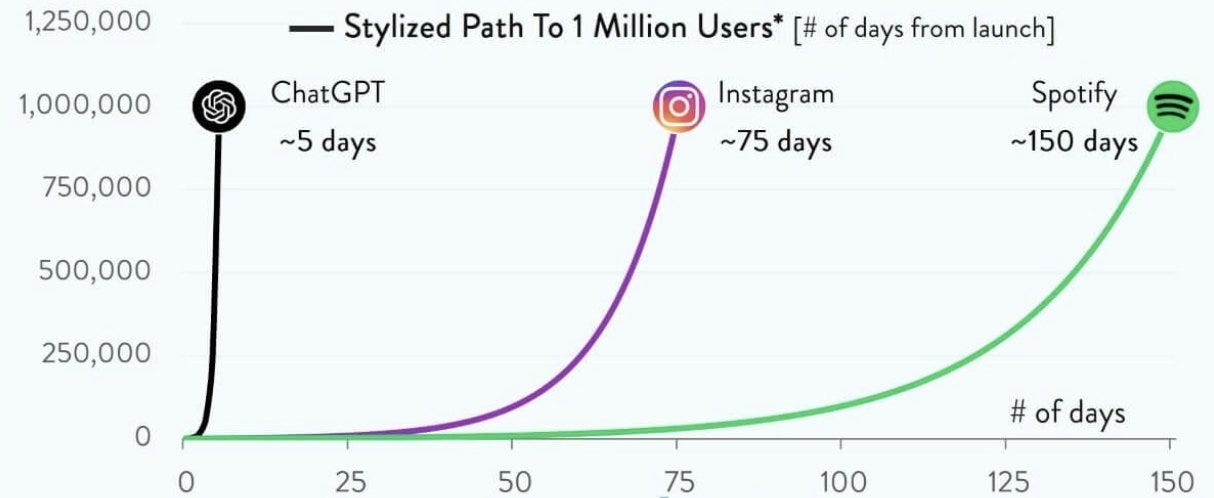
ChatGPT was the fastest-growing application of all time, by far; the level of user interest and media attention it garnered was unlike anything the world has ever ever seen.
The fictional AI of our childhoods was no longer just a story; ChatGPT made it a reality. It reignited every conversation about AI, from futures of abundance and leisure to terrified technophobic claims regarding the rise of Skynet.
Everyone started to worry about their jobs because ChatGPT showed the world that AI was capable of doing everything we didn’t think was possible.
Hey AI companies, where’d you get that data from?
7 months later the lawsuits against AI companies began.
The first shot across the bow came from book authors Mona Awad and Paul Tremblay, asserting their IP had been used without permission to train GPT.
They had a right to be concerned.
In the early days of ChatGPT, you could ask it nearly any question about a book you wanted to, and if it had been included in the training data, ChatGPT would answer similar to how it repeated The Art of War earlier.
It was clear that books played a big part in training ChatGPT (they admitted it themselves), and the assertion by authors and publishers was that OpenAI had violated copyright law in doing so.
Dozens of similar lawsuits have since followed, with many authors and publishers of all kinds asserting their IP had been used “without consent, without credit, and without compensation”, as we discussed in the first article.
Book Publishers, however, were not alone in their complaints against OpenAI and the other AI companies.
Digital publishers like the New York Times filed lawsuits claiming Microsoft had violated copyright law, and online forums such as StackOverflow (a popular website for software engineers to find answers to technical questions) and Reddit became extremely vocal as they observed massive hits to their traffic as a result of ChatGPT.
ChatGPT represented a new channel for people to directly and quickly find answers to their questions, without having to browse endless forums for the one relevant response.
Solving for Consent, Credit and Compensation
In retaliation, Reddit made a dramatic change to their API (API stands for Application Programmable Interface. API’s are how software applications communicate with one another. We'll talk more about APIs later, so remember this definition for when we get there in case you haven’t heard of it before).
Data that was once available to the public for free now required payment
This change caused a massive controversy in the Reddit community, even warranting its own Wikipedia entry, but this new way of thinking had a tremendous impact on Reddit’s business model.
No longer able to access the data for free, Google struck a $60MM per year deal with Reddit to license their data. It presented one of the largest deals to date where a digital publisher explicitly licensed their data for AI use.
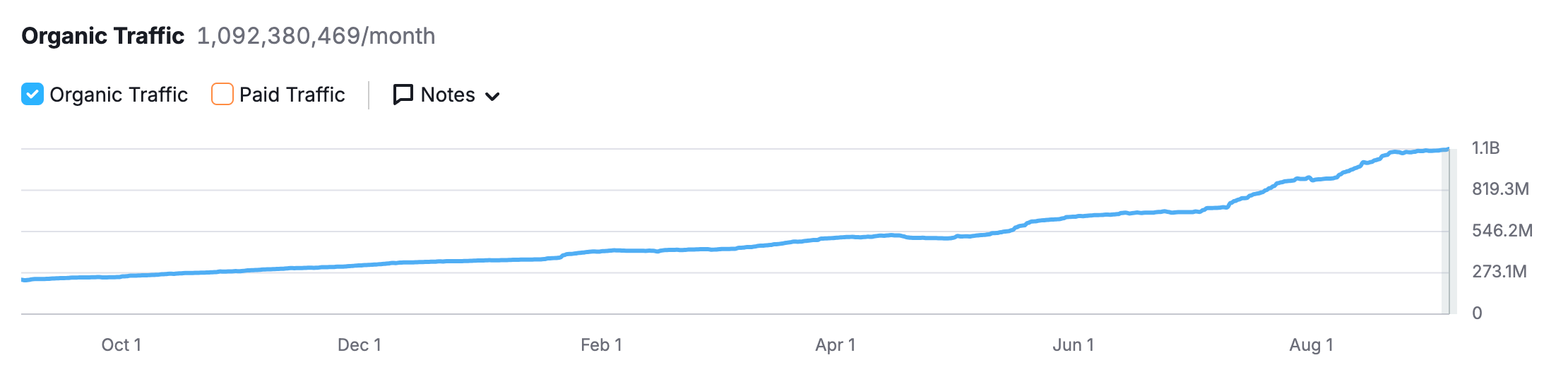
Reddit now provides some of the most popular data used to power Google's AI Search Responses; this is one of the reasons why you may have started to notice Reddit showing up at the top of so many of your search results in recent months.
The three core concerns have been addressed in the partnership:
- Google operates with Reddit’s consent to leverage their content for AI (both in training their model and through search, which is Google's version of inference)
- Reddit gets credit, or links to its website in the Google search results
- Reddit is compensated by the licensing deal where Google uses its data to train their LLMs. Reddit has also likely seen a huge boost in their advertising business due to the massive traffic increase
It appears that digital publishers and AI companies have found a path forward.
Licensing data for use with AI: a new revenue model for digital publishers
This model of AI companies licensing data from providers is becoming increasingly common.
Recently, a wave of well-known digital publishers such as Conde Nast, Time, Vox Media, and The Atlantic made announcements that they have struck “strategic partnerships” with OpenAI to license their content.
NewsCorp (parent company of media giants such as The Wall Street Journal and The New Yorker) announced a huge 5-year, $250MM partnership with OpenAI for access to content across all of their properties.
The model of AI companies like OpenAI, Microsoft and Google licensing data to be used in training, and then providing credit and compensation through inference appears to have a strong foundation.
It’s working with Reddit, and while I have some concerns about the longevity of this model, I have no reason not to believe it won’t work in the near term for the other digital publishers as well.
Digital publisher content licensing for usage with AI companies
You may notice I keep saying “digital” publishers, which I have done intentionally to distinguish them from “book” publishers.
AI partnerships are happening with book publishers; Wiley recently announced a $44MM deal to license their content with AI companies, which we’ll discuss further in the next article.
The licensing model digital publishers are establishing has critical differences when it comes to how it could apply to book publishing, which is where Alex’s “…unless something changes…” most directly applies.
First, let's dig in a bit further and build a better understanding of how these digital publisher / AI partnerships work.
Disclaimer. None of the details of the aforementioned partnerships are public, so the following is my expert analysis of what’s happening.
In this section, we discuss several key concepts around AI.
If your understanding of these topics is rusty, please check out my “Beginner’s Guide to Understanding Generative AI”. In that article, one of the ideas I discuss is how the data in an LLM becomes obsolete starting on the first day of training.
From that day on, an LLM’s ability to generate responses based on its internally trained data ends, and it requires external data sources to respond about anything more recent.
For this reason, data usage in training and inference must be considered separately for license partnerships.
In the case of the Google and Reddit partnership, two parts map directly to how LLMs work:
- Training. Google has access to historical Reddit data for use in training their LLM. Once the historical data makes its way into the LLM, just like our piano music analogy from before, it cannot be removed and is referencable forever.
- Inference. Google has access to both historical and new Reddit data via the API for use in inference (again, inference is called “search” in Google’s case). This access allows it to provide current results via “RAG”, and it is the mechanism by which the search results reference the source data they draw from.
Distinguishing these use cases allows us to think through how the three concerns previously mentioned — consent, credit, and compensation — work their way into the partnerships. We will do so first by analyzing the 3C’s through the lens of Training, and then through Inference.
Digital Publisher Content Licensing: Training
Consent and Compensation
Data used to train an LLM is licensed on a perpetual, “per model” basis . This to me is the logical case, simply due to the impracticality of any other alternative.
Given the time and resources it takes to train a single LLM combined with the semi-permanent and persistent nature of that LLM after it has been trained, there wouldn’t be a way to “continue” to license data with time.
Since granting a perpetual use license to train multiple LLMs would be a lost business opportunity (each iterative model is essentially a new business), data is licensed every time a new LLM is trained and released.
For instance, OpenAI has released GPT-2, GPT-3, GPT-3.5-Turbo, GPT-4, GPT-4o, GPT-4o1, etc., and under this licensing model, the data would need to be re-licensed to cover each successive model, or the license adjusted to include scope for all of them.
While the publisher’s data may be used to train the LLM, this doesn’t mean the LLM can openly use the data in inference for representation or recreation.
These days, training for the closed-source LLMs takes copyright into account — like the example I provided at the beginning of this series— if they don’t have permission, they don’t disclose the details (example).
Researchers learn a lot about an LLM after it is published and they study how it is used, and continually make improvements from one generation to the next.
For instance, they may learn that some parts of the training data are repetitive and therefore unnecessary, or there may be gaps in the training data, requiring them to acquire new data.
Each new LLM leverages its unique training dataset, which suggests new licensing considerations for each successive generation.
Credit
2 scenarios using our piano analogy (from the “Beginner's Guide to Understanding Generative AI”) to help illustrate the challenges of providing “credit” in training, and why the only real way to provide credit in training is at the model level (i.e. the digital publisher partnership announcements previously discussed).
Scenario #1: Inability to provide sources
If you were to perform the piece you memorized for your friend, they may ask you for details about the song.
You could tell them the composer, the title of the song, and perhaps the characteristics of the song, but you couldn’t provide them with a copy of the sheet music itself.
Your friend would have no way of confirming the details — they wouldn’t be able to jump to a specific page in the sheet music to see if you played a specific part correctly, check if you hit every note, or even learn it for themselves.
They could only take you for your word and would have to look up details on their own if they were sufficiently invested to do so.
Scenario #2: Training soup makes exact attribution impossible
Suppose the first song inspires you to continue to practice. You learn hundreds of other songs and eventually start to compose your own music.
The skills you learned in practicing all of the songs helped you to learn how to compose, but the music you write is completely your own.
Then one day, you perform your new music for your friend. When they ask about the song, you tell them it’s an original you wrote.
You might be able to share some of the songs that inspired your style, but ultimately, what you've created is something new — providing exact attribution is nearly an impossible feat.
These scenarios illustrate the challenges an LLM would have in providing credit based on the training data alone.
However, for the sake of argument, pretend an LLM could provide credit for every single word it generates by telling you exactly every piece of training data that contributed to selecting that word.
You'd still be left with the challenge that the “credit” is self-referential. Like the pianist's inability to provide source material for their music, the LLM cannot provide the source of the data because that's just not how they work.
They can only generate accurate predictions of the data, there is no way for them to provide sources or external references to the source material.
For this reason, unless an LLM can point to an external data source, credit is unlikely to be provided via training alone — and so similar to the ChatGPT example from before — LLMs will likely continue to avoid scenarios where permission of representation or replication is required to display content.
Digital Publisher Content Licensing: Inference
This section provides an inroad to illustrate the power of pairing inference with training.
Consent and Compensation
In the partnership with Google, Reddit provides access not only to historical data but also to all the current data on their site. This is how they can offer up-to-date results to any query.
The way Reddit governs access to all of its data is via its API.
If Google violates the terms of their partnership or fails to properly compensate Reddit for their data, like the piano music, Reddit would not be able to extract their data from the LLM itself since they already licensed their data for training, and the training is now complete.
But, they would be able to restrict Google’s access to all of the historical and recent data used in search — because that’s how an API works — an API is all about controlling who has access to what data, and ultimately governing how the data consumer uses that data.
For everyone else, Reddit has a consumption model in place — where they charge for every time someone accesses their API.
Credit
This, from my perspective, is one of the greatest strengths of inference.
Because inference requires feeding source data into the context window, it makes it easy to determine the source of the response back from the LLM when it references it.
Back to the piano analogy.
From all of your practice, you’re now able to play the piano by sight — meaning you may have never played a piano piece before, but now because you’re so good, you can sit down to a new piece and play as if you’ve been practicing it for years.
Before you sit down to perform for a group of people, one of your friends gives you a piece of sheet music from an artist you've never heard of, and asks you to play it.
Never having practiced it, you’re able to perform it perfectly for the audience, perhaps even adding in some of your personal distinct style flourishes as you play it.
When someone comes up to you afterward and asks about the song, you're able to pull out the sheet music and point to it for them — your source is readily at hand, as it provided the input for your performance.
For an LLM this is similar.
With Google, when you ask a question, not only can they respond with the AI Google search result, but they can easily provide links to the source (like a post on Reddit) they drew their data from so the user can go back and reference the original content. They can do this both for new data as well as data used to train the original model.
Inference with RAG is a powerful resource when it comes to leveraging AI with private data sets. It allows the data to remain secret and separate from the LLM, yet still provides a way for the LLM to use it and generate a response.
This is likely how digital publishers and AI companies will continue to address the concern around “credit”.
The devil is in the details
I am not oblivious to the fact that this last section is starting to get into the weeds. I'd apologize, except the fact that you've read this far means that you must be eating this up.
That said, this is the level of detail required to understand what needs to change to enable books and AI to have a future together — so please stick with me.
The key points from this previous section have been summarized in the matrix below.

Thus far, we have seen that licensing of digital publisher content is becoming more and more common — the partnership models appear to be working.
We have examined how the primary concerns of digital publishers are likely addressed in those partnerships.
In the next article, we’ll look at the differences between digital and book publishers, and what needs to be different in their AI content licensing partnerships.
This was the second article in a four-part series discussing the Future of AI and Books. If you'd like to continue reading, click the relevant link below.
- AI and the Future of Book Publishing
- The Current State of AI and Publishing
- Why the Established AI Content Licensing Model Breaks with Books
- Vision and Call to Action for the Future of Books and AI
If you're a bit fuzzy on some of the AI terminology used in this article, I'd recommend reading my “Beginner's Guide to Understanding Generative AI”.
.jpg)

